
OpenAI官方说法是:GPT-5.6系列会在将来几周周全开放,但今朝先应美国当局请求,在Codex和API中向一小群“值得信赖的合作伙伴”进行有限预览。
让我们先来懂得一下已公开的谍报。

关于有限预览
最高等和GPT 5.5同价
OpenAI此次给GPT-5.6分了三档:Sol、Terra、Luna。
按照官方说法,Sol是旗舰模型,Terra是面向日常工作的均衡模型,Luna则是快速、便宜的轻量模型。
三档模型一口气全放了出来,根本对应大年夜模型产品里最常见的三层构造:最强模型负责才能上限,中心模型负责大年夜多半日常义务,轻量模型负责速度、成本和高并发调用。
OpenAI对Terra的介绍没有那么长,但定位很清楚:它是面向日常工作的均衡模型。
从价格就能看出三者的层级。
按照OpenAI颁布的API价格,GPT-5.6按每100万token计费:Sol是输入5美元、输出30美元;Terra是输入2.5美元、输出15美元;Luna是输入1美元、输出6美元。
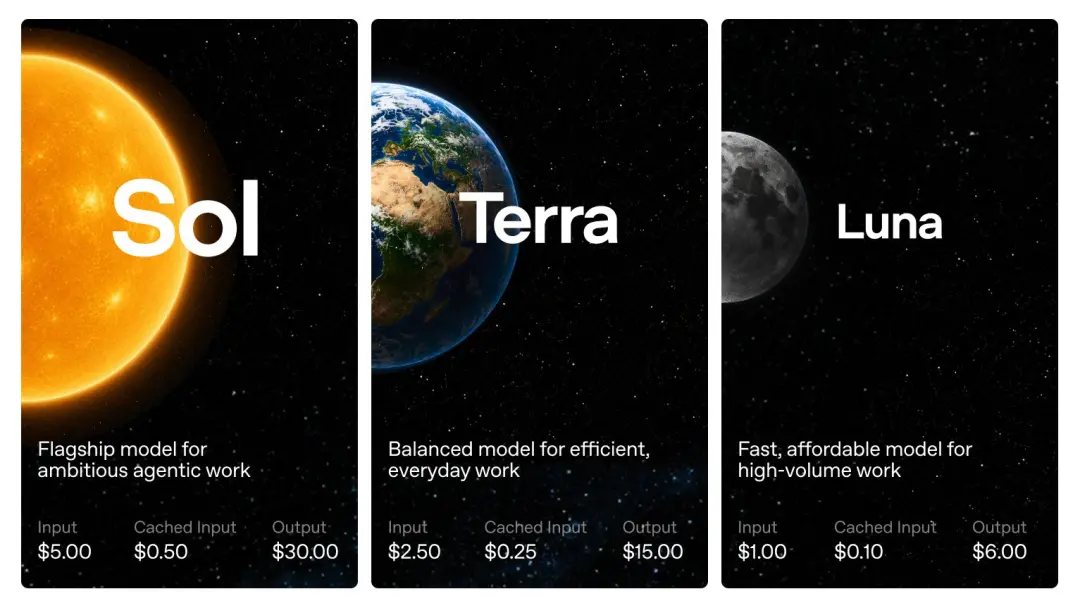
信赖大年夜家可能留意到了:GPT-5.6 Sol固然是新一代旗舰模型,但价格对齐的是GPT-5.5标准版,而不是GPT-5.5 Pro。
Terra则直接降到GPT-5.5的一半,Luna只有GPT-5.5的五分之一。
GPT-5.5 Pro依然是当前OpenAI最贵的模型,价格是输入30美元/百万token,输出180美元/百万token,价格是GPT-5.5标准版和GPT-5.6 Sol的6倍。也不知道之后会不会再出一个“更合适专业义务”的GPT-5.6 Universe(只是开打趣)。
通俗懂得,就是让Sol有更多时光想清楚问题、花更长时光进行深度推理,合适那些不克不及靠第一反响解决的复杂义务。
在OpenAI的假想中,Terra很可能才是GPT-5.6系列里最常用的那一档。通俗办公义务很多时刻不须要Sol那样的最高才能,但须要稳定、便宜、好用。
Sol是此次GPT-5.6系列里的最高等,也是官方通知布告里花最多篇幅介绍的模型。
OpenAI把GPT-5.6 Sol称为今朝最强模型,重点展示了它在写代码、生物研究和收集安然上的才能。
简单说,Sol的定位是“最会干活的模型”,它对应的不是通俗聊天场景,是更复杂、更接近真实工作的义务。
比如在代码场景里,它可以环绕一个目标持续推动:先懂得问题,再拆步调,然后调用对象、运行敕令、检查成果,掉足了再改,直到义务完成。
为了支撑Sol处理更难的义务,OpenAI给GPT-5.6引入了两个新机制。
第一个叫max reasoning effort,可以翻译成“最大年夜推理强度”。
第二个叫ultra mode,可以懂得为“超强模式”。
这个模式的重点是让多个子智能体一路介入复杂义务,可以懂得为:以前是一个AI助手本身干活,如今是一个“AI经理”带着几个小助手分头处理问题,从而加快复杂工作的推动。

Terminal-Bench 2.1就是一个更接近真实开辟流程的测试,考的是模型能不克不及在敕令行情况里一步步解决问题。GPT-5.6 Sol在该测试中拿到了88.8%的高分,Ultra模式下得分更高。
OpenAI特别提到,等模型更广泛开放时,还会颁布一套更完全的评测成果。
Terra是中心档。
也就是说,它不必定寻求最强,但要在后果、速度和成本之间取得均衡。官方强调,Terra的才能接近GPT-5.5,但价格便宜一半。
在Terminal-Bench 2.1测试中,GPT-5.6 Terra拿到了84.3%,和Claude Fable 5持平。
Luna则是最低成本档。
并且,此次有限预览是“应美国当局请求”进行的,介入预览的合作伙伴名单已经和美国当局共享。
OpenAI对Luna的定位也很简单:快,便宜,它合适大年夜量、高频、对成本敏感的义务。
比如批量摘要、文本分类、信息抽取、简单问答等等,这些义务本身不必定复杂,但调用量可能异常大年夜。Luna的感化,就是把这些轻量义务用更低成本跑起来。
这三档模型,Sol负责最高才能,Terra负责日常工作,Luna负责速度和成本,听起来花哨,但OpenAI只是把大年夜模型行业已经很成熟的分层从新包装了一遍。
不过我认为名字什么的并不重要,便宜好用就行。

性价比这一块儿
只看官方通知布告,GPT-5.6 Sol此次放出的benchmark并不算多。OpenAI本身也说,如今只是为了让外界提前懂得模型机能,所以先分享一组评估成果。
但放出来的这组benchmark偏向很明白,集中展示了三个范畴:代码、生物学和收集安然。
前面提到的Terminal-Bench 2.1就属于代码偏向,它考的是模型能不克不及在敕令行情况里完成真实开辟流程,包含筹划、反复修改、调用对象和验证成果。
除了代码,OpenAI还重点提到了一个生物学benchmark:GeneBench v1。

GeneBench v1评估的是长周期的基因组学和定量生物学分析义务,重点看模型能不克不及处理更接近真实科研流程的分析问题。
按照OpenAI的说法,GPT-5.6 Sol在GeneBench v1上比GPT-5.5表示更强,并且应用的token更少。
第三个重点偏向是收集安然。OpenAI称,GPT-5.6 Sol是它今朝最强的收集安然模型,尤其是在长周期安然义务上(包含马脚研究和马脚应用相干义务)。
这里有一个benchmark叫 ExploitBench——它不是一般的安然问答,是更接近马脚应用处景的评估。
OpenAI称,在ExploitBench上,GPT-5.6 Sol的表示可以和Mythos Preview媲美,但只用了大年夜约三分之一的输出token。
固然,官方给出的这张图上还有必定差距。
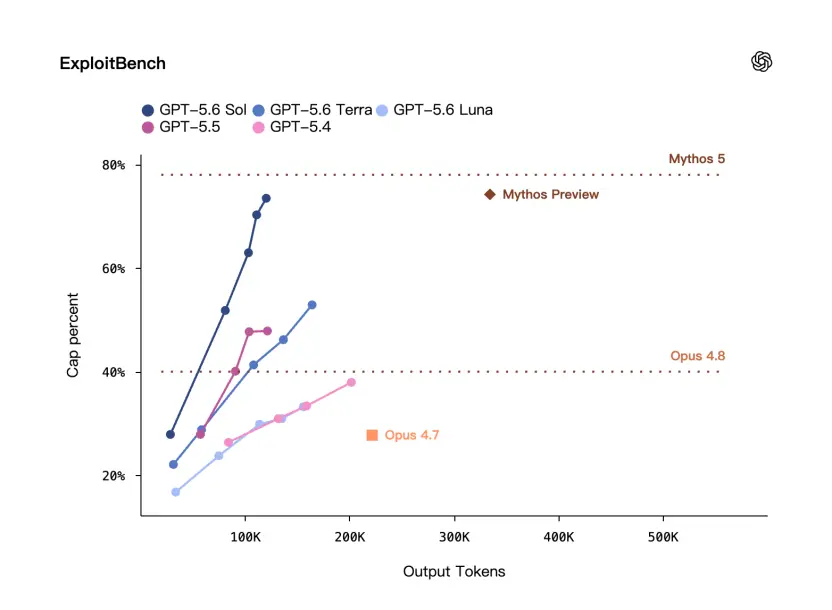
可以看出,OpenAI此次反复强调:他们在才能强的同时,效力也特高。
更少的输出token,意味着模型完成同类义务时可能更简洁、更少绕路,也可能意味实在际调用成本更可控。
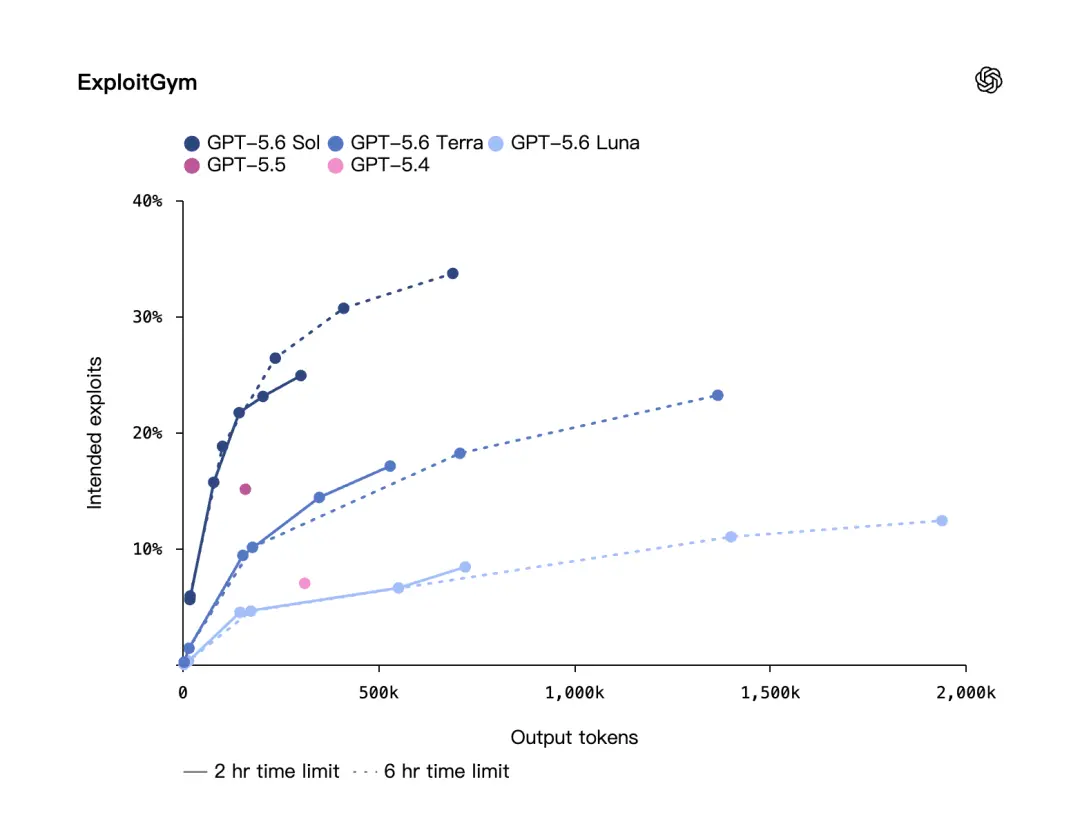
OpenAI还提到了另一个收集安然benchmark:ExploitGym。
这个benchmark是UC Berkeley研究人员与OpenAI以及其他前沿实验室合作创建的。OpenAI说,在ExploitGym上,GPT-5.6 Sol、Terra、Luna三档模型都显示出明显的收集安然才能晋升,并且跟着推理强度进步,表示也会变强。
意思是,GPT-5.6的晋升不只是模型本体变强,也和推理方法有关。给模型更多时光思虑、让它做更长链条的推理,成果就会更好。

假如说Sol、Terra、Luna是GPT-5.6外面上的变更,那么更值得存眷的工作是,OpenAI此次没有直接周全开放。
按照官方通知布告,今朝GPT-5.6只会先在Codex和API中,向一小群“值得信赖的合作伙伴”进行有限预览。
比来一段时光,美国当局正在明显加强对前沿AI模型的介入,尤其是那些具备更强代码、收集安然和agent才能的模型。
本年6月,美国当局宣布了新的AI收集安然相干行政令,提出要建立一个自愿框架,让前沿模型开辟者在模型更广泛宣布前,与当局进行接触和评估。
司法界对这份行政令的解读是:它名义上不是强迫许可、也不是正式审批轨制,但已经搭起了一个当局介入模型宣布前评估的轨制框架。
OpenAI本身也在通知布告里解释,之所以采取这种方法,是为了和当局一路摸索一个可反复的流程,用来支撑将来的模型宣布。
当局介入背后,核心原因是收集安然。
官方通知布告里,收集安然占了异常大年夜的篇幅:OpenAI一边强调GPT-5.6 Sol是它今朝最强的收集安然模型,能在马脚研究、马脚分析、安然防御等长周期义务上供给更强赞助;另一边又花了大年夜量篇幅解释,它没有跨过本身的Cyber Critical门槛。
OpenAI的预备框架里,把高风险才能分成不合等级。达到High,意味着模型可能放大年夜已有的严重风险;达到Critical,则意味着模型可能带来前所未有的新型严重风险。
OpenAI反复强调GPT-5.6 Sol没有达到Cyber Critical,其实是在告诉当局、客户和"大众,":这个模型很强,尤其在收集安然义务上很强,但还没有强到可以自立完成最危险的收集进击链。
收集安然才能就像一把双刃剑,它越强,越能帮防御者找马脚、写补丁、做安然测试;但也正因为它很强,当局也会担心它被滥用。
GPT-5.6 Sol“先小范围预览、名单与当局共享”的宣布模式,可以看做前沿模型的宣布流程里,第一次出现了清楚的当局介入陈迹。
听起来很花哨,像一个新的模型宇宙。但它其实照样我们熟悉的那套产品分层:一个最强的旗舰模型,一个日常应用的均衡模型,一个便宜、快速、合适大年夜范围调用的轻量模型。
固然OpenAI承认此次宣布须要和当局一路摸索流程,但它也在官方通知布告里明白解释,他们不认为这种当局拜访流程应当成为经久默认机制。
来由是:假如最强对象老是被迁延开放,用户、开辟者、企业、收集防御者和全球合作伙伴都邑更晚拿到最好的对象。
某种意义上,前沿模型正在进入一个新的宣布阶段。
昔时夜模型的才能集中到代码、生物、收集安然和智能体履行这些范畴,它就会开端被当成一种可能影响实际世界安然的技巧。
而一旦技巧被如许对待,宣布权就很难再完全留在公司本身手里。





发表评论 取消回复