

换句话说,在全球编程模型的竞技场上,阿里是独一杀进这张牌桌的中国厂商,仅次于Anthropic,位列第二。
Qwen3.7-Max闯入全球前五
独一非Claude模型
其其实Code Arena放榜之前,Qwen3.7-Max在海外开辟者圈子里已经杀出了名声。
Atomic Chat做了一场硬碰硬的比较,让Opus 4.7、GPT-5.5和Qwen3.7-Max同台竞技,义务是写一个能自我练习的俄罗斯方块AI。

全程零高低文退化、零指令漂移、零逝世轮回!
另一位海外开辟者选择让Qwen3.7-Max构建了一个宇宙的3D模型,后果足以用震动形容。

在“3D像素风微缩浮屠模型”的生成义务中,Qwen3.7-Max的输出速度和质量同样周全胜出。




阁下
开辟者Paul Couvert更是盛赞,Qwen3.7-Max接入Hermes Agent和OpenCode之后,根本可以替掉落GPT-5.5和Opus 4.7。


编程,太能打了
不过跑分再高,不如真刀真枪拉出来练练。
我们给Qwen3.7-Max安排了一场硬核的“赛车游戏”挑衅。
一段具体的prompt丢进去,不一会儿工夫,Qwen3.7-Max直出一个可玩的HTML的文件。

第一版有个小bug,A/D转向键阁下搞反了。
但经由第二轮简单对话微调,一个别验完全的3D赛车游戏就跑了起来。

打开的刹时,说实话,有点被惊到了。
4车同台,3圈环形赛道竞速,赛道上散落着100多枚金币,碰着障碍物会减速、掉控。
赛后成就面板,排名、用时、金币数、最快单圈,一项不缺。
但真正让人不测的,是两个只有Qwen3.7-Max做到的细节。
一个是开端界面。四个模型横向测完,只有它给游戏做了一个正经的开端页面,点“Start”才进入比赛。其他三家满是打开即跑,连个标题画面都没有。
另一个是音效。prompt最后附了一条请求,加上发念头轰鸣和吃金币的音效。 四个模型里,也只有它把这个bonus吃进去了,引擎声和金币叮咚都安排上了。

再看看其他选手的表示。
Gemini 3.5 Flash的画面明显薄弱了一档,缺乏那种呼之欲出的立体感。
今天,Qwen3.7-Max凭借着1541分的成就楔进了第四的地位,卡在Opus 4.6 Thinking和Opus 4.6之间。
UI构造也有问题,仪表盘信息分散在屏幕四角,视觉核心一盘散沙。
比拟之下,Qwen3.7-Max的处理方法是把关键指标集中到画面中心,更相符玩家视线的天然落点。

Claude Opus 4.6的后果,有点让人一言难尽了。
最后是GPT-5.5。
可以看到,画面质感确切比前两家强了不少,操作起来也更流畅。
成果,Qwen3.7-Max不仅只用$1.32的token成本就把Opus 4.7和GPT-5.5都超出了,并且机能还晋升了56%。
但不知道为什么,金币被做成了黄色的“甜甜圈”……

造型倒是小事。关键是,Gemini、Claude、ChatGPT三家都修了好几轮bug才跑通全部功能。
只有Qwen3.7-Max首轮生成就根本可玩。
跑分接近,实测不虚,价格只有几分之一。剩下的结论,等开辟者用脚投票就行了。
Agent时代的“基座”模型
Qwen3.7-Max之所以能在最卷的编程擂台上打出如斯程度,谜底就藏在它的产品定位里。
几天前,阿里宣布Qwen3.7-Max的时刻,给了它一个异常特别的标签:Agent基座模型。
它生来,就是为长时光自立履行义务设计的模型。
内测数据显示,在一次自立编程义务中,Qwen3.7-Max持续运行35个小时,履行1158次对象调用。
也就是,让模型在持续变更的模仿情况中做跨越一千步的持续决定计划,本身建立假设、根据反馈调剂策略,并且不克不及因为跑太久就“高低文腐化”。
最毕生成的代码相较于Triton参考实现,达到了惊人的10倍几何平均加快。

更令人震动的是它的“持久战”才能——
在推演进行到第30个小时之后,模型依然保持灵敏,持续发掘出新的优化空间。
不得不说,这件事的难点不在1000次对象调用本身。MCP协定铺开之后,调1000次对象不算稀奇。
难点在于,35小时的连贯推理。
这说清楚明了一个反直觉的现象,Qwen3.7-Max在Claude Code、OpenClaw、Qwen Code这几个框架里的表示都很稳,没有出现“在自家框架里很强、换一个就拉胯”的情况。
绝大年夜多半模型跑长义务时会崩盘:要么高低文越积越乱,前半段定的目标到后面忘得干清干净;要么进入逝世轮回,反复测验测验同一个掉败的筹划。
Qwen3.7-Max把“持续做对事”这件事,做出来了。
核心技巧揭秘
Qwen3.7-Max这波编程跃升,我们懂得核心可能与两个练习办法的进级有关。
第一个是,情况扩大。
Qwen3.7-Max在做编程练习时,每个义务会被拆成三个自力维度,义务本身、履行框架、验证方法,三者自由组合。
同一道题,有时刻在Claude Code的框架里做,有时刻在OpenClaw里做,有时刻换一种验证方法。
后果就像一个练习生被轮岗到了所有项目组。它被迫学会的是解决问题的通用策略,不是“在某个特定框架里怎么取巧”。

第二个进级是,长程自立履行。
在练习中,团队引入了“动态累积生计博弈”框架。
这里有一个直不雅的数据,YC-Bench模仿创业公司经营一全年,Qwen3.7-Max做到了208万美元营收,是上一代(105万)的两倍。
更关键的是,它展示出了策略进化,中期碰到危机能自立调剂偏向,辨认并拉黑恶意客户,最终收敛到稳定的履行轮回。
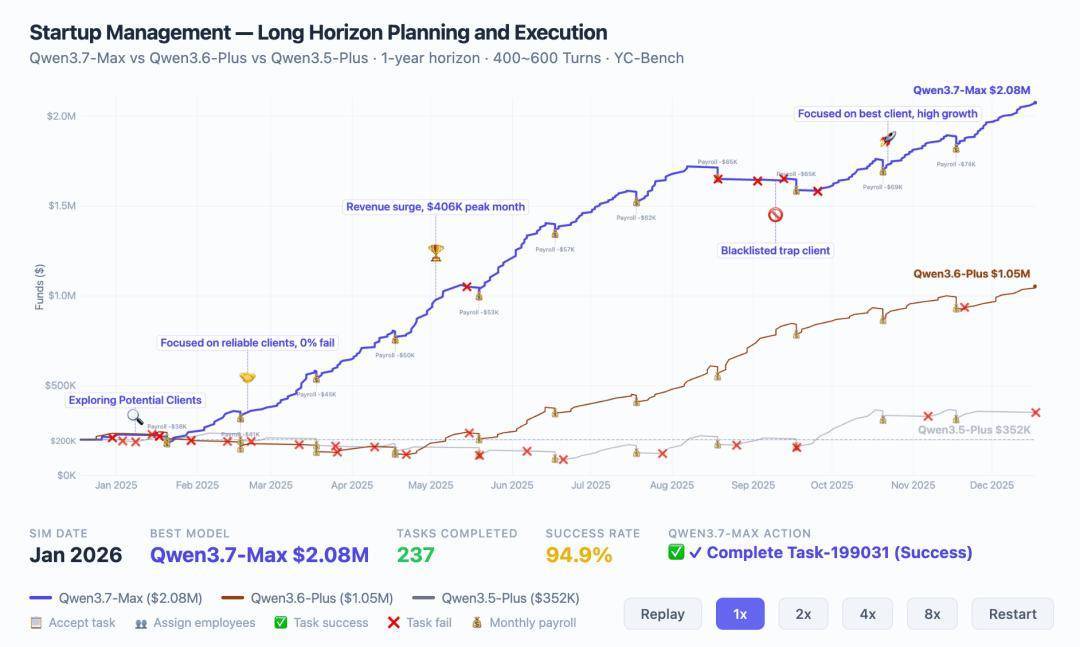
这就是35小时kernel优化案例的底层支撑,也是为什么在Kernel Bench L3上,Qwen3.7-Max能让96%的场景跑出加快后果。
而编程还只是第一个疆场。这套长程推理加对象调用的基本底细,指向的是一个更大年夜的野心——通用Agent基座。
编程决赛,多了一个搅局者
Code Arena上线至今,考的从来都是硬活,多步推理、对象编排、完全项目交付,满是Agent级的真刀真枪。
不仅赛道上金币少得可怜,并且3辆AI赛车几乎同步行驶,毫无随机性,像复制粘贴出来的。
在这条Claude统治了大年夜半年的赛道上,它给出了本身的答复,中国模型不只是追赶者,也可所以定义者。
全球编程模型的比赛,已经不再是硅谷的独角戏了。





发表评论 取消回复