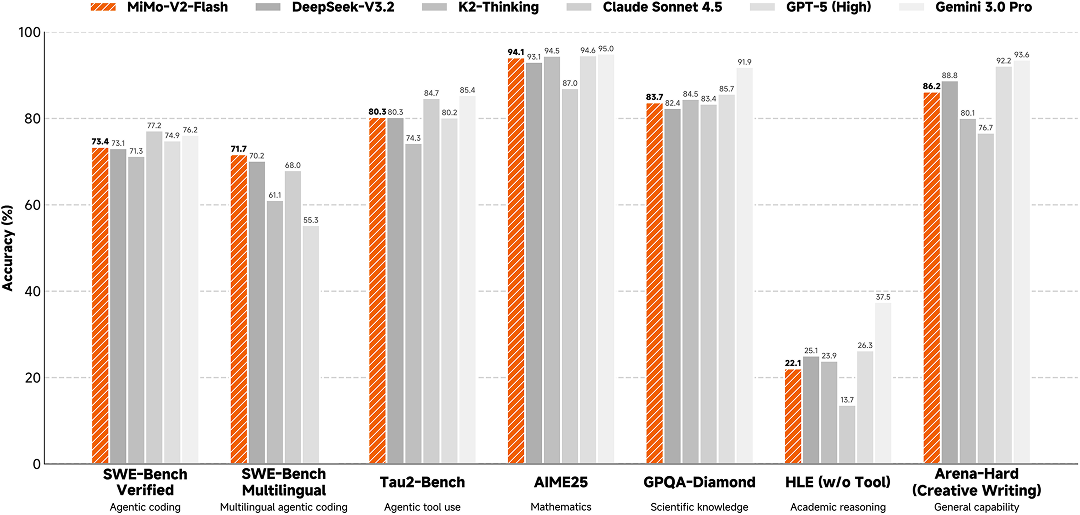
小米正式宣布开源 Xiaomi MiMo-V2-Flash,这是小米专为极致推理效力自研的总参数 309B(激活15B)的 MoE 模型,经由过程引入 Hybrid 留意力架构立异及多层 MTP 推理加快,在多个 Agent 测评基准长进入全球开源模型 Top 2;代码才能跨越所有开源模型,比肩标杆闭源模型 Claude 4.5 Sonnet,但推理价格仅为其 2.5% 且生成速度晋升至 2 倍,成功将大年夜模型后果和推理效力推向极致。
Xiaomi MiMo-V2-Flash 模型权重和推理代码均周全开源。API 限时免费,体验 Web Demo 已上线。

MiMo-V2-Flash 模型架构如下:
MiMo-V2-Flash 模型构造要点:
- 混淆留意力
采取 5:1 的 Sliding Window Attention (SWA) 与 Global Attention(GA)混淆构造,128 窗口大年夜小,原生 32K 外扩 256K 练习。经前期大年夜量实验发明,SWA 简单、高效、易用,展示了比主流 Linear Attention 综合更佳的通用、长文和推理才能,并供给了固定大年夜小的 KV Cache 从而极易适配现有练习和推理 Infra 框架。
- MTP推理加快
引入 MTP (Multi-Token Prediction) 练习晋升基座才能的同时,在推理阶段经由过程并行验证 MTP Token,打破了传统 Decoding 在大年夜 Batch 下的显存带宽瓶颈,实测在 3 层 MTP 情况下可实现 2.8~3.6 的接收长度和 2.0~2.6 的实际加快比。
整体而言,得益于模型构造与训推 Infra 的深度融合与立异,MiMo-V2-Flash 可以在不合的硬件上经由过程调优 Batch Size 和 MTP 层数来最大年夜化释放 GPU 算力,从而展示出更高的吞吐,并保持优良的低时延以及极致推理机能。

拜访 platform.xiaomimimo.com,可以一键兼容 Claude Code、Cursor、Cline、Kilo Code 等框架。
即刻登录 MiMo Studio Web:aistudio.xiaomimimo.com,免费体验模型。

发表评论 取消回复