据通义大年夜模型官方消息,通义百聆宣布其语音大年夜模型Fun-CosyVoice3与Fun-ASR完成重大年夜进级并同步开源。此次进级聚焦核心机能与实用性,为开辟者与企业供给更强大年夜的语音AI对象。
https://github.com/FunAudioLLM/Fun-ASR(GitHub)

Fun-CosyVoice3:及时、精准的语音合成
模型首包延迟降低50%,实现“输入即发声”。中英混说缺点率大年夜幅降低56.4%,并支撑9种说话、18种方言及情感控制。其开源版本Fun-CosyVoice3-0.5B具备优良的zero-shot音色克隆才能。
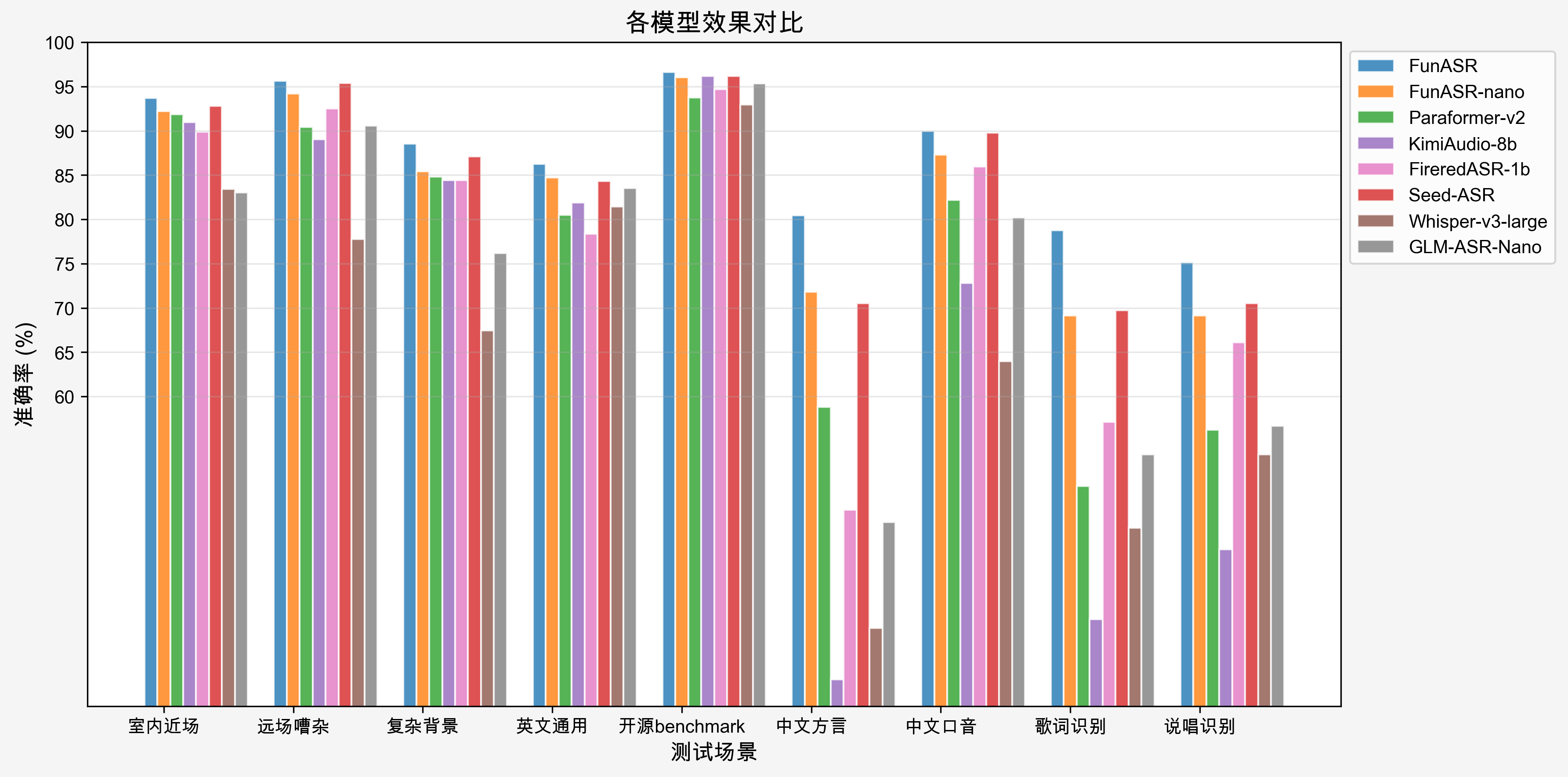
Fun-ASR:强悍抗干扰的语音辨认
模型已在魔搭、HuggingFace及GitHub等平台开源,支撑本地安排与二次开辟。
https://funaudiollm.github.io/funasr/(GitHub.io)
https://modelscope.cn/studios/FunAudioLLM/Fun-ASR-Nano/(国内体验demo)
https://huggingface.co/spaces/FunAudioLLM/Fun-ASR-Nano(海外体验demo)
https://modelscope.cn/models/FunAudioLLM/fun-asr-nano-2512(国内模型仓库)
该模型在嘈杂情况下精确率达93%,新增歌词与说唱辨认功能。支撑31种说话自由混说与多种中文方言,流式辨认首字延迟仅160毫秒。轻量化版本Fun-ASR-Nano-0.8B同步开源,推理成本更低。
https://huggingface.co/FunAudioLLM/Fun-ASR-Nano-2512(海外模型仓库)

发表评论 取消回复