据悉,昇思MindSpore开源社区将于 2025 年 12 月 25 日在杭州举办昇思人工智能框架峰会。本次峰会在展区、CodeLabs、WorkShop等环节供给了丰富的案例,本篇文章以个中CodeLabs中的DeepSeek-OCR为例,深刻介绍其技巧实现,更多案例迎接来到峰会现场进行体验和实操。
当文本碰见视觉,AI模型正从新定义信息紧缩的界线
在人工智能快速成长的今天,DeepSeek团队于2025年10月推出的DeepSeek-OCR模型带来了一场文本处理范式的革命。这一立异模型不仅实现了10倍紧缩率下97%的解码精度,更摸索了经由过程视觉模态紧缩长高低文的全新路径。而昇思MindSpore框架的day0支撑才能,则为这一前沿技巧的快速安排应用供给了坚实基本。
DeepSeek-OCR:从新定义文本紧缩的界线
DeepSeek-OCR 是 DeepSeek AI 于 2025 年 10 月 宣布的多模态模型,以摸索视觉 - 文本紧缩界线为核心目标,为文档辨认、图像转文本供给立异筹划。其采取 DeepEncoder 视觉编码器与 DeepSeek3B-MoE-A570M 混淆专家解码器的双模块架构,从 LLM 视角从新定义视觉编码器功能,聚焦 “文档解码所需起码视觉 token” 这一核心问题,对研究 “一图胜千言” 道理具有重要意义。
基于Expert归并的加快筹划经由过程FFN权重预融合技巧,将多个专家的计算义务归并为单一计算流:
模型的核心技巧冲破表如今三个方面:
高紧缩比下的精度保持:实验注解,当文本令牌数量在视觉令牌数量的10倍以内(即紧缩比
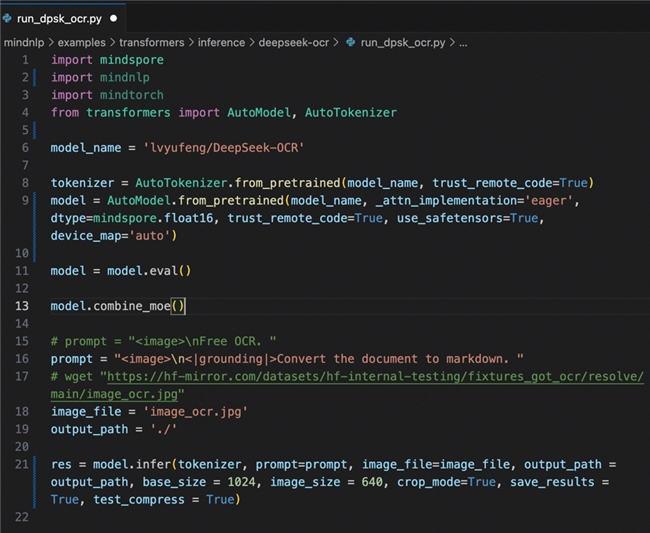
分层视觉编码设计:DeepEncoder采取三阶段处理流程——起首应用SAM-base进行局部感知(窗口留意力看清细节),然后经由过程卷积层进行16倍下采样,最后应用CLIP-large进行全局语义懂得。这种设计可以或许在高分辨率输入下保持低激活内存。 多分辨率支撑:模型供给Tiny/Small/Base/Large/Gundam五种设备,支撑从512×512到1280×1280的不合分辨率输入,个中Gundam版本专门针对大年夜尺寸复杂文档优化。 Day0支撑:MindSpore NLP快速支撑DeepSeek-OCR 代码如下图所示: MindSpore NLP作为基于昇思MindSpore的开源NLP库,其核心优势在于与Hugging Face生态的周全兼容。这种兼容性设计使得任何基于Transformers架构的模型都能在昇思MindSpore框架上无缝运行,为DeepSeek-OCR的快速安排供给了技巧基本。 新增2行代码,即可实现基于昇思MindSpore的一键适配 具体而言,MindSpore NLP供给了与Hugging Face完全一致的API接口,开辟者可以应用熟悉的AutoModel、AutoTokenizer等类直接加载和运行模型。这种设计极大年夜降低了模型迁徙的技巧门槛,确保新宣布的模型可以或许实现“day0”支撑。 基于MindSpore NLP的兼容性特点,DeepSeek-OCR在昇思MindSpore上的安排变得异常简洁。全部过程重要包含三个关键步调: • 情况设备:安装MindSpore NLP及相干依附库,确保昇思MindSpore版本兼容性 • 模型加载:应用MindSpore NLP+Transformers接口直接加载DeepSeek-OCR预练习权重 • 推理履行:调用同一的API进行文档懂得和视觉-文本紧缩义务 基于Expert归并的小MoE模型加快:权重融合计算优化策略 这种标准化流程清除了复杂的模型转换环节,使研究者可以或许专注于应用开辟而非情况适配。无论是处理扫描文档、PDF转换照样长文本紧缩,开辟者都可以应用熟悉的Hugging Face编程习惯在昇思MindSpore生态中高效运行DeepSeek-OCR,完全案例详见: (https://github.com/mindspore-lab/mindnlp/tree/master/examples/transformers/inference/deepseek-ocr)。 在实际机能方面,DeepSeek-OCR在OmniDocBench测试中表示卓越,仅应用100个视觉token即超出GOT-OCR2.0模型,800个视觉token优于MinerU2.0模型。支撑PDF转图像、批量处理及Markdown格局输出。 如下图所示,运行脚本后,模型可辨认扫描件中的文字,并转换为MarkDown文件。 DeepSeek-OCR的解码器采取混淆专家(MoE)架构,激活参数约570M。针对MoE模型练习中的机能挑衅,昇思MindSpore供给了基于Expert归并的优化筹划,明显晋升了小MoE模型的效力。 基于Expert归并的小MoE模型加快技巧核心在于经由过程权重预融合策略,将传统动态路由计算转化为同一计算流,从根本上解决MoE架构中的Host端调剂瓶颈问题。 1、传统MoE计算瓶颈分析 传统MoE模型采取“专家视角”的计算模式,其核心瓶颈表如今两个方面: • 权重归并机制:在模型初始化阶段,将所有专家的FFN层权重进行拼接融合,形成一个同一的超大年夜型权重矩阵。以8专家MoE层为例,每个专家FFN层的输入维度为d_model,中心维度为d_ffn,归并后的权重矩阵外形从8个自力的[d_model, d_ffn]矩阵改变为同一的[8×d_model, d_ffn]矩阵。 • 细碎算子调剂开销:传统实现方法须要遍历每个专家,为每个专家自力履行前向计算。这种轮回遍历模式导致大年夜量小范围算子的频繁调剂,特别是当专家数量增多时,Host端的算子下发和调剂开销呈线性增长。 • 负载不均衡问题:因为不合专家处理的token数量差别明显,计算过程中轻易出现负载不均衡。某些热点专家须要处理大年夜量token,而其他专家可能处于余暇状况,这种不均衡进一步加剧了设备应用率的降低。 2、权重预融合技巧道理 • 同一计算流程:路由收集输出的选择权重不再用于动态激活不合专家,而是作为加权系数直策应用于融合后的计算成果。具体而言,模型起首经由过程融合权重矩阵履行一次同一的前向计算,然后根据路由权重对输出进行加权组合,避免了传统的专家遍历过程。 针对DeepSeekV2(DeepSeek-OCR LLM模块)的改进代码如下: 在昇思MindSpore+昇腾的软硬件协同情况中,这一技巧大年夜幅晋升了DeepSeek-OCR的履行速度,相较于原版实现,推理token生成的机能晋升3-4x,算力应用率由8%晋升至30%+。这种基于Expert归并的加快思路,为小范围MoE模型的安排供给了一种新的优化范式,特别是在对推理延迟敏感的端侧和应用处景中具有重要价值。 总结 DeepSeek-OCR与昇思MindSpore在昇腾硬件上的深度结合,标记住文档智能处理进入了一个全新的成长阶段。这一技巧组合不仅展示了前沿AI模型的立异潜力,更表现了从算法、框架到硬件的全栈优化价值。 瞻望将来,跟着多模态大年夜模型技巧的持续演进和昇腾算力基本举措措施的赓续完美,OCR模型与昇思MindSpore的深度结合将释放更大年夜潜力。从简单的文档辨认到复杂的常识抽取,从单页处理到跨文档分析,这一技巧路径正在开启文档智能的新篇章,为企业数字化转型和AI普惠应用供给坚实的技巧底座。 本次在杭州举办的昇思人工智能框架峰会,将会邀请思惟领袖、专家学者、企业领军人物及明星开辟者等产学研用代表,共探技巧成长趋势、分享立异成果与实践经验。迎接各界精英共赴前沿之约,联袂打造开放、协同、可持续的人工智能框架新生态! 





发表评论 取消回复